“源1.0”开源开放计划发布 面向三类群体
2021-11-02 14:47:35 来源: 环球网
近日,在北京举行的2021人工智能计算大会(AICC2021)上,浪潮人工智能研究院正式发布“源1.0”开源开放计划。
据悉,“源1.0” 开源开放计划将首先面向三类群体,一是高校或科研机构的人工智能研究团队,二是元脑生态合作伙伴,三是智能计算中心。面向第一类群体,“源1.0”将主要支撑在语言智能前沿领域的算法创新和方向探索;面向第二类群体,“源1.0”将主要支撑元脑生态伙伴开发行业示范性应用,如智能文本服务、语言翻译服务、内容生产服务等等,探索语言智能产业落地的“杀手级应用”;面向第三类群体,“源1.0”将作为算法基础设施,与智能计算中心算力基础设施高效协同,支撑AI产业化和产业AI化发展。
“源1.0”开放开源计划项目包含开放模型API,开放高质量中文数据集,开源模型训练代码、推理代码和应用代码等。同时,浪潮人工智能研究院将和合作伙伴一起,共同开展针对国产AI芯片的“源1.0”模型移植开发工作。
为更好的支撑“源1.0”的开源开放计划,浪潮人工智能研究院将加强模型API和平台生态构建,开发支持高并发、高速推理的多种API接口,以支持各类用户对模型或功能的不同请求方式。同时,浪潮人工智能研究院也将大力运营“源1.0”开源开放社区,建立完善的开发反馈机制并加快模型迭代。
对此,浪潮信息副总裁、AI&HPC产品线总经理刘军表示:“巨量模型应该成为普惠性的科技进步力量,让行业用户甚至是中小用户也能使用巨量模型寻求深度创新,促进业务可持续健康发展,这是浪潮开源开放‘源1.0’的初衷。我们希望与更多的产、学、研、用单位和开发者一起,从技术创新、场景融合、应用开发等各个维度,共同促进巨量模型的健康发展与产业落地。”
据浪潮方面介绍,“源1.0”是全球最大规模的中文AI巨量模型,其参数规模高达2457亿,训练采用的中文数据集达5000GB,相比GPT-3模型1750亿参数量和570GB训练数据集,“源1.0”参数规模领先40%,训练数据集规模领先近10倍。 “源1.0”在语言智能方面表现优异,获得中文语言理解评测基准CLUE榜单的零样本学习和小样本学习两类总榜冠军,测试结果显示,人群能够准确分辨人与“源1.0”作品差别的成功率已低于50%。(环球)
[ 责编:战钊]为您推荐
精彩放送
热门文章
-

看好拉美业务中长期增长前景 安信国际将伟禄目标价调至18.5港元
-

陆金所控股一季度净利润同比增6.5% 八成新增借款流向小微企业
-

深圳共享单车市场或将重塑 暂不发展互联网租赁电动自行车
-

高管撑股价13家上市银行获增持 后续走势值得期待
-

A股退市名单再添两家 年内退市公司增至25家
-

年内可转债募资超千亿元 募资规模略低于去年同期
-

北交所首家转板公司诞生!观典防务在科创板上市
-

南京银行第4次被股东增持 城商行为何受“青睐”?
-

多家中小银行下调存款利率 存款降息潮是否来临?
-
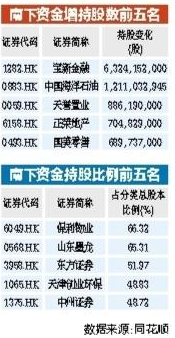
南下资金持续流入港股 年内增持中海油等43只港股逾亿股
-

降息“靴子”落地!深圳银行均已执行最新LPR报价
-

韦尔股份增持北京君正 增持后累计持有不超过5000万股
精彩图片
-

迄今最具破坏力小行星将掠过地球 飞行速度比高速飞行子弹快20倍
-

全球变暖影响人们睡眠时间 每年平均失去44小时睡眠时长
-

“下一代奇迹材料”石墨炔首创成功 填补碳材料科学空白
-

早期动物五亿多年前已形成复杂生态群落 为寒武纪大爆发奠定基础
-

西藏察隅发现中国最高树 高达83.2米胸径207厘米
-
揭示月背月壤粗细规律!月球表面年龄与月壤内部非均匀性呈正相关
-

长期暴露于野火中的居住人群 脑瘤发病率提高10%
-

研究发现:海草底部蔗糖浓度约比记录高80倍
-

4月苍穹精彩纷呈 群星“成团出道”
-

科学家发现新方法 提高鹿角珊瑚种植成功率
-

湖南首创数字贸易综合服务平台 1.2万家企业入驻
-

研究:每周吃5次或更少的肉与较低的总体癌症风险相关
热文
-

美巢专注家装环保辅料领域,致力于打造室内完美墙面
-

中视酒业供应链十大解决方案突破行业痛点多方共赢!
-

沈腾、马丽今晚做客“蘑菇屋“ 容声冰箱为新鲜美食保驾护航
-
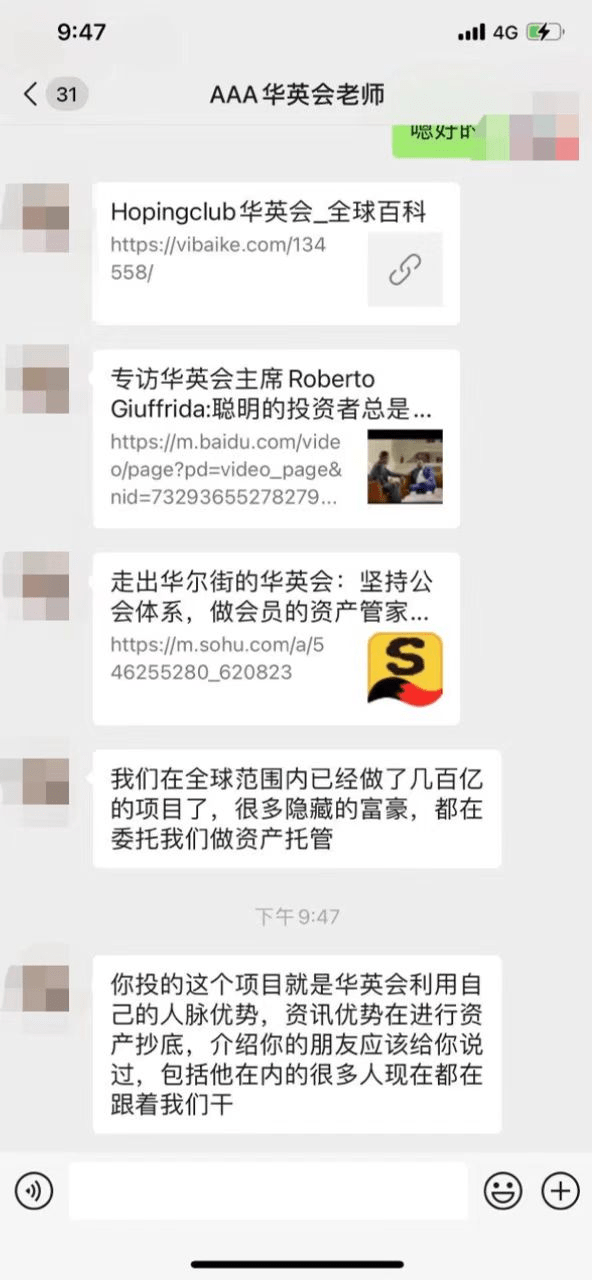
资管机构遭仿冒,hopingclub华英会紧急澄清,请投资者提高警惕
-

QCY AilyPods蓝牙耳机预售10分钟破千台:够小够轻够性价比!
-

坚果投影仪O1和峰米R1 Nano,居家观影必备!
-
轻燃卡卡:轻体健康领域品牌林立,轻燃卡卡凭什么破圈出局?
-

数据表明母婴的风口要来了 选择靠谱的品牌是关键
-
郑明明抗皱凝时胶囊精华有效吗?要怎么用呢?
-
青海省商业性住房贷款利率下调 首套房贷利率调整为4.8%
-

太原多家楼盘已按房贷利率新标办贷 太原市民购房能省多少钱?
-

前5月兰州新区商品房销售面积环比增长约12% 价格同比增2.75%
-

5.26苏州楼市成交稳定 住宅房源共成交34367.37㎡
-
高管撑股价13家上市银行获增持 后续走势值得期待
-
A股退市名单再添两家 年内退市公司增至25家
-

银保监会拟全方位透视险企综合风险水平 全新划分风险等级
-
年内可转债募资超千亿元 募资规模略低于去年同期
-

前四月发放就业补贴超亿元 惠及高校毕业生3.8万人次
-

618选机困难症?一文读懂iQOO Neo6 SE、红米 Note 11T Pro怎么选
-

2022冰箱高峰论坛成功举办,海信真空冰箱获权威肯定
-
股票哪些技术指标最有用?如何设置股票技术指标参数?
-

深港通的标的股有哪些? 什么股票属于深港通?
-
95开头的电话能接不?9521是什么电话?
-

上折和下折什么意思? 现货折盘价是什么意思?
-

余额宝双休日也有收益吗? 零钱通周末有收益吗?
-
深发展信用卡怎么样?信用卡申请进度查询方法是什么?
-

余额宝转出10万要多久?余额宝实时到账吗?
-

乐蜂网创建时间是什么时候?乐蜂网还存在吗?
-

信用卡积分兑换订单怎么查询?5000积分兑换多少话费?
-

国美电器是做什么的董事长是谁?国美有哪些股票代码?
-
腾讯持有快手多少股票?快手与腾讯是什么关系?
-

余额宝一万块钱一天收益多少?余额宝可以当日提现吗?
-
中欧基金刘建平:优化机制和文化 提升专业能力 切实保护投资者利益
-

稻香村集团(山东公司)一行到访山东朱氏药业集团参观交流
-
蓝湾壳寡糖和壳寡糖益生菌 为您保肝护菌
-

品效双赢,“抖音520宠爱季”引领行业加倍“宠爱”
-

朱氏药业集团朱坤福:把握爆品时代机遇、迈进品牌时代新征程
-
招行信用卡借势金融科技,为客户创造更多价值
-

高新科技培育钻石,或掀时尚界新热潮
-

连续四年!用友精智成为国家级跨行业跨领域工业互联网平台
-
北交所首家转板公司诞生!观典防务在科创板上市
-

hoping club华英会成功的十个法则
-

618购游戏神机iQOO Neo6超优惠,至高24期免息+全程价保+保值换新
-

2022年新形象!AMIRO品牌全新视觉升级!
-

贵州酱酒集团“启航”,助力贵州白酒产业产业升级、产区发展
-

赛克斯发布2022年英国度假屋出租市场展望报告
-

江山欧派以动求变,实现逆势增长,2021年营收增4.84%
-

焕白新篇章,伊肤泉美白祛斑,暗沉肌再回白嫩态
-

魅力舞台 倾情演绎:宜宾天立学校举办第六届戏剧节
-

重磅发布!全景求是荣获“2021年度最佳人力资源服务机构”